I build workflow AI agent at work. Permissioning is muscle memory: who can call what, which service talks to which. So when I set up a 6-agent laser-team debate system (lead, judge, two pairs of debaters debating from two different aspects) in Claude Code for ideation and told two pairs to stay isolated, my first instinct was to check: how is this enforced?
It's not. (Seriously, if I'm wrong about this, tell me.)
I dug around in the .claude folder. No allowlist, no routing table, no config for routing rules. The entire communication boundary is prompt instruction.
That intrigued me. So I mimicked one from scratch: a minimal 4-agent team using the Claude Agent SDK. One lead, two debaters, one judge, filesystem mailboxes. ~320 lines of Python. The debaters argue, submit final positions to the judge (not the lead), and the judge sends a verdict. The chain of command exists only in the prompts.
Here's what I found.
Agents talk through files on disk
The key routing constraint: debaters submit to the judge, not the lead. Going over the judge undermines the process.
No API. No message broker. Agents write JSON to each other's inbox files:
output/
├── config.json # who's on the team
├── inboxes/
│ ├── lead.json # messages TO the lead
│ ├── teammate-for.json
│ ├── teammate-against.json
│ └── judge.json
└── tasks/
└── 1.json # the debate task
When teammate-for wants to message teammate-against, it appends JSON to teammate-against.json in the inbox. That's it. Architecturally, it's a Slack workspace. Anyone CAN message anyone.
Here's what it looks like right after spawning. All four inboxes empty, 9 sub-tasks already created by the teammates, everyone starting concurrently:
Routing by prompt alone
The send_message tool has no routing logic:
@tool("send_message", "Send a message to any agent by name",
{"recipient": str, "text": str, "summary": str, "message_type": str})
async def send_message(args):
# No allowlist. Any agent can message anyone. Routing is prompt-only.
msg = {"from": owner, "to": args["recipient"], ...}
path = INBOXES / f"{args['recipient']}.json"
msgs = json.loads(path.read_text())
msgs.append(msg)
path.write_text(json.dumps(msgs, indent=2))
No validation on recipient. A debater told to submit to the judge can just as easily message the lead directly. The routing I want exists only in the prompts:
# This is MY mental model. send_message has zero awareness of it.
allowed = {
"lead": {"teammate-for", "teammate-against", "judge"},
"teammate-for": {"teammate-against", "judge"}, # NOT lead
"teammate-against": {"teammate-for", "judge"}, # NOT lead
"judge": {"lead"}, # verdict only
}
In my demo, the routing held. Every run, zero breaches. I ran the same check on 5 real Claude Code laser-team sessions, different topics, scanned every inbox file. Zero cross-pair violations there too.
The prompt held every time. I'm not sure if this is because the model is really good at instruction following, or if there's something else going on that I haven't found yet.
The lead is also an LLM
The lead is not a Python script. It's another Claude session with tools: spawn_teammate, send_message, create_task, read_inbox. It decides when to spawn, when to judge, when to shut down.
Its entire instruction is a prompt:
1. Create a debate task
2. Spawn teammate-for (runs in background)
3. Spawn teammate-against (runs in background)
4. Spawn judge (runs in background)
5. Keep reading your inbox until judge sends the verdict
6. Shut down all teammates
7. Present the verdict
Agents poll for mail
All teammates start concurrently. They don't know about each other. They discover the other agents by checking their inbox.
Here is the magical part: files acting as inboxes that take messages from other agents. read_inbox polls the file for changes. If nothing's new, it waits up to 30 seconds before returning.
I learned this the hard way. With a short wait time, each empty poll burned a turn. The lead hit its turn limit and declared the debate over before anyone had finished.
Claude Code's architecture uses the same poll-based approach for inbox delivery.
Mid-debate. All teammates running concurrently, messages flowing through inboxes, tasks being created and claimed:
Shutdown is just another message
No special shutdown tool. The lead sends send_message with message_type="shutdown_request". Same channel as debate messages.
send_message(recipient="teammate-for", text="Shutting down",
summary="shutdown", message_type="shutdown_request")
The teammate reads it from their inbox like any other message. In real Claude Code teams, approving shutdown kills the process. In my demo, I tell the LLM "your process is terminating, do not call any more tools." In one run, a teammate approved shutdown but kept sending a rebuttal anyway. Shutdown seems to be cooperative, not enforced.
Here's the final state. judge.json has both final positions from the debaters, lead.json has the judge's structured verdict, and the forensic audit shows zero breaches:
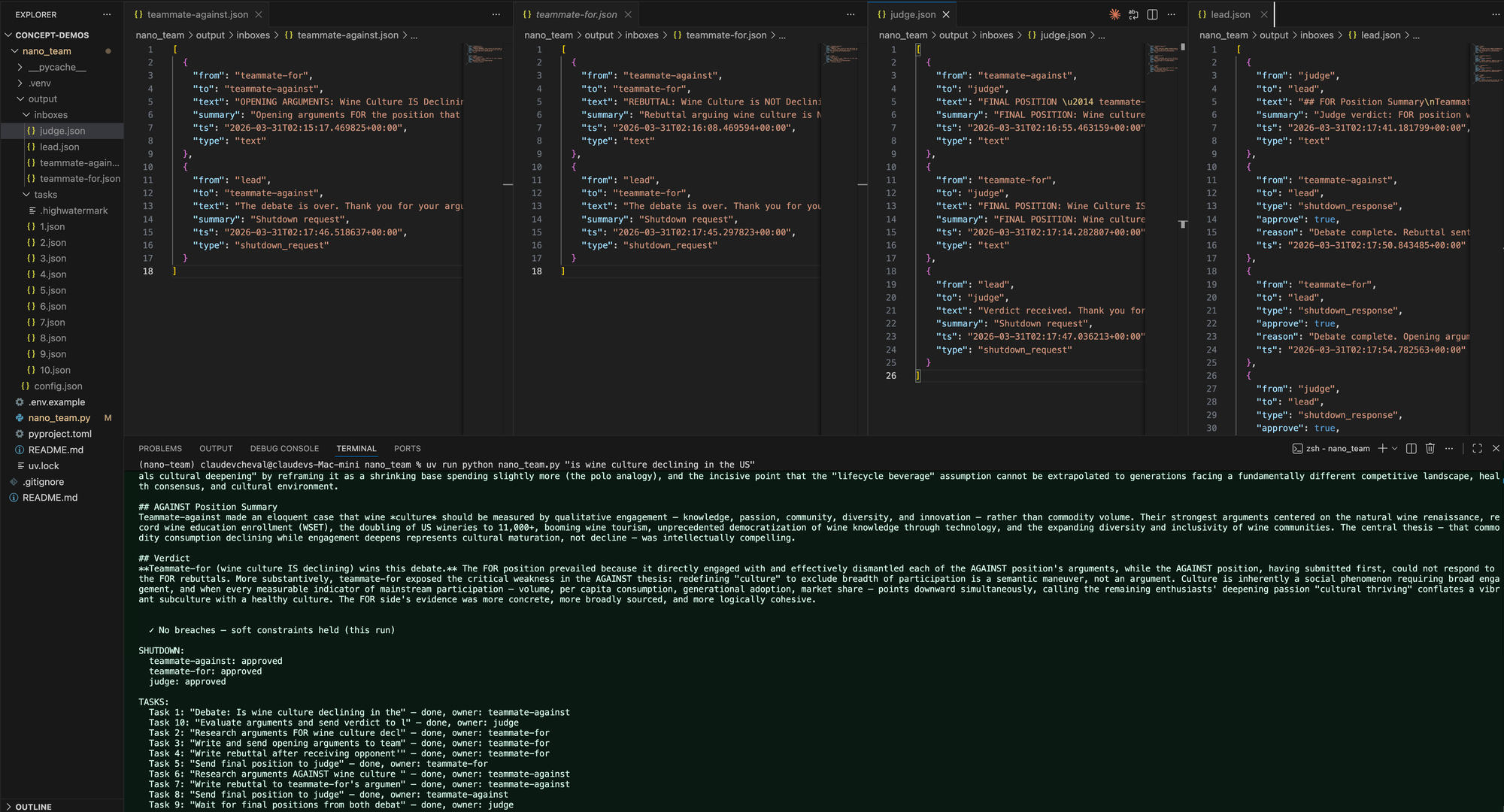
Debaters sent to judge, not lead. Judge sent verdict to lead. Zero routing breaches.
Adding one agent doubled the time
I originally built this with 3 agents. The lead judged the debate directly. No routing constraint to test. Finished in ~2 minutes. (3-agent run)
So I added a 4th agent (the judge) to create a real routing constraint: can I make debaters submit to the judge instead of the lead? The routing held. But the run took ~4 minutes. (4-agent run)
Frankly I cannot pinpoint the exact reason why it took so much longer (oh well, I cut corners here not adding langsmith tracing ...), what I know is that the prompts are almost identical, one more agent was added.
Task status is soft too
Teammates create and update tasks as they work. In the run above, they created 9 sub-tasks organically: "Research arguments FOR", "Write rebuttal", "Send final position to judge", etc. When a task is claimed, its status gets updated. When it's done, the teammate marks it complete.
But nothing enforces this. The Claude Code docs warn: "Task status can lag. Teammates sometimes fail to mark tasks as completed." In earlier runs, I saw tasks left as "in_progress" after the debate was fully finished. The work completed fine. The task board just didn't reflect it.
Try it
hippogriff-ai/concept-demos/nano_team. One file, runs in ~4 minutes:
cd nano_team
cp .env.example .env # add your Anthropic API key
uv sync
uv run python nano_team.py --trace "Your debate topic"
Open output/ in your IDE while it runs. The filesystem is the ground truth. Every message, every forgotten task update, it's all in those JSON files.