Anthropic's Memory API elevates file-based memory into a distributed primitive: per-file linearizability via compare-and-swap (CAS). The agent sees a filesystem. The system handles consistency.
This post is my best guess at the design. Public docs cover the surface: mounts, access modes, optimistic concurrency. The internals are inferred. The framing is the point; specific implementation claims may be wrong.
Why files
Files are the right primitive because models have got better at managing them. From Anthropic's own framing: "Claude Code can accomplish complex tasks across domains using local code execution and filesystems." Lance Martin also added that: files are shareable and interpretable in ways embeddings are not.
There's also the challenge to get RAG right: selecting an embedding model, tuning chunk sizes, versioning the index. As model capability grows, file-based memory is the high-ROI choice. The agent does the curation, after all, why waste the model's ability?
How the agent sees memory
When you attach a memory store to a session, it mounts at /mnt/memory/<store-name>/ and a short note about the mount goes into the system prompt. That's how an agent becomes aware of which stores are available. The agent doesn't need a special tool. read_file and grep work because the mount is represented as a directory.
The docs recommend keeping files under 100KB and splitting context across many focused files instead of one big one. grep finds the right file. read_file pulls only what's needed. Context stays lean.
Safety
Read-only mounts are the answer to prompt injection on shared memory. From the docs: "if the agent processes untrusted input ... a successful prompt injection could write malicious content into the store. Later sessions then read that content as trusted memory." Access mode is set at session creation, enforced at runtime.
Every change generates a new version of the store. The audit trail is built in. You don't add it later.
My guess at the design
Data model. Two levels: a memory store, which is the workspace-scoped unit, and individual memories (files) inside it. Versioning sits at the store level for snapshots, but linearizability is at the file level.
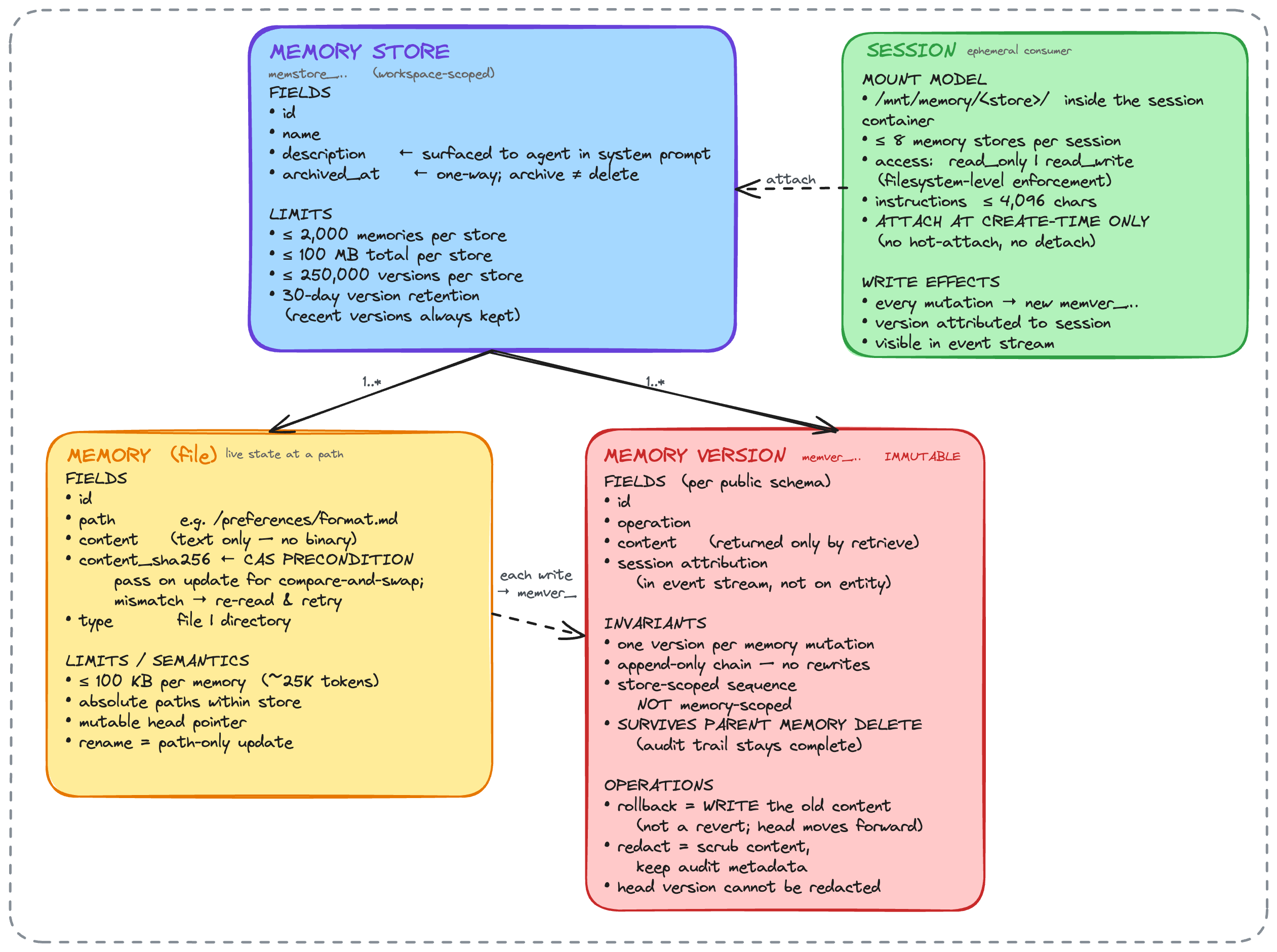
Write consistency. The docs phrase it as "safe content edits (optimistic concurrency)". That reminds me of CAS. Same pattern S3 ships for multi-writer apps: each write carries the expected version; if the version moved, the write fails and the agent retries. This effectively prevents lost writes.
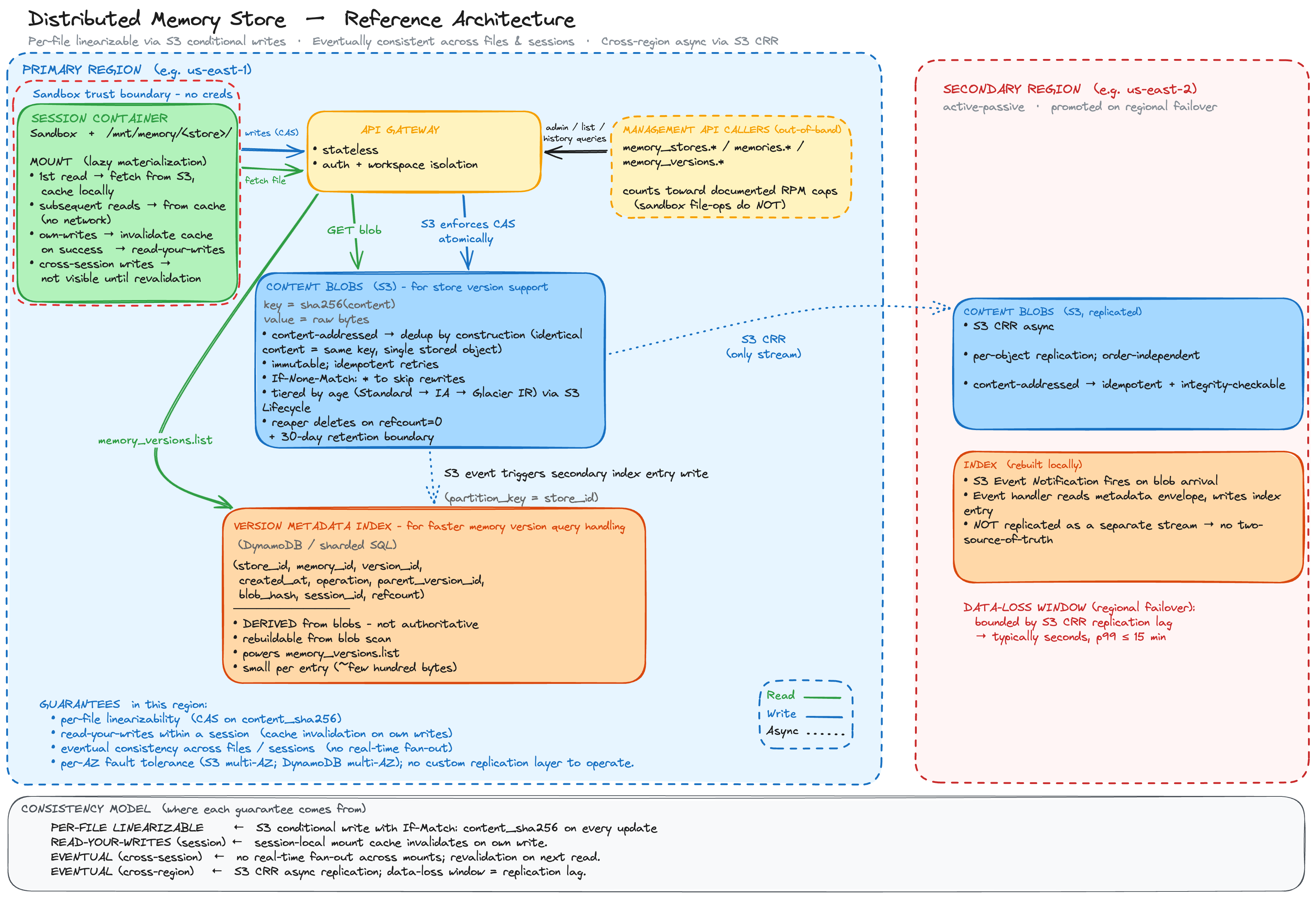
Read consistency. Eventual. My guess: the store mounts lazily into the sandbox. First read on a file pulls bytes; subsequent reads serve from a local cache so grep stays fast. The cache invalidates on local writes. For other sessions' writes you'd need explicit polling or invalidation. The trade-off: cross-session writes aren't visible until the cache refreshes.
In my opinion that's fine. A memory entry going stale for a couple minutes should not materially change answer quality. Linearizability matters at write time. Reads can be looser.
Version log. Written once, read rarely. Append-only fits. Blobs live in S3, with log entries carrying version_id, parent_version_id, blob_hash, operation. S3 keys by content hash, supporting memory_versions.list would be inefficient if relying on S3 alone. So it makes sense to introduce a Dynamo DB to store secondary index, which is derived from the S3 blobs, makes looksup by store_id or memory_id fast.
Specifically, for DynamoDB, a partition key on store_id matches the access pattern: list memories by store, fast.
Multi-region. The most plausible path: S3 cross-region replication fires a notification on blob arrival, an event handler in the secondary region reads the blob and writes the local secondary index. Same shape as primary, just driven by replication events.